Comment les microdonnées HTML contribuent-elles à l'accessibilité ?

J'étudie le HTML à partir d'un blog sur l'accessibilité écrit par un développeur aveugle. J'étais curieux de savoir comment ils structuraient leur balisage et je voulais voir s'il y avait des éléments supplémentaires qui le rendaient encore plus accessible.
Le balisage de ce blog particulier semblait aller au-delà de ce que j'appellerais la structure sémantique de base ; article , header , en-têtes ordonnés logiquement, etc. Il comportait également certains attributs que j'avais déjà reconnus ( item-something ?) mais je n'ai jamais pris le temps d'en apprendre davantage sur : Microdata .
Qu'est-ce que les microdonnées ?
Les microdonnées, telles que décrites à partir de schema.org et/ou de la spécification Microdata , sont des attributs permettant aux navigateurs de créer une structure de données lisible par machine que les navigateurs peuvent utiliser. Il peut être considéré comme des paires key:value un peu comme un objet JSON .
Après avoir lu la spécification et examiné quelques exemples, il semble y avoir trois attributs principaux à connaître :
- Tout ce qui a l'attribut booléen
itemscopeest l' item ou la "chose" des données que vous définissez. C'est plus ou moins un conteneur ou "point de départ" de données. - Un élément a besoin de l'attribut
itemtypeavec une valeur d'URL spécifique pour décrire plus en détail le vocabulaire ou la "catégorie" de l'objet. En d'autres termes, ce qui est acceptable en tant qu'éléments de données enfants. - Un dernier attribut à inclure dans la définition d'un élément est
itemprop. Il s'agit du nom de propriété du nœud de données que nous sommes en train de définir.
Voici le coup de pied :
Les microdonnées permettent de localiser et d'organiser le contenu pour le mode lecteur du navigateur .
Qu'est-ce que le mode lecteur ?
Le mode lecteur est une fonctionnalité du navigateur qui permet à quelqu'un de se concentrer plus facilement sur le contenu en :
- masquer les éléments de page non essentiels tels que la navigation, les barres latérales, les pieds de page et les annonces
- modifier la taille, le contraste et la mise en page du texte de la page pour une meilleure lisibilité
- suppression des animations gênantes
Cela aide à créer une expérience plus accessible pour les personnes ayant des troubles cognitifs ou des troubles d'apprentissage, comme la dyslexie, car cela supprime tout ce qui est inutile sur la page.
Ajouter des microdonnées à un modèle d'article de blog
Écrivons du code HTML pour un modèle d'article de blog et ajoutons les attributs de microdonnées qui aident à créer une meilleure expérience en mode lecteur.
1. Conteneur d'articles
Pour l'élément de conteneur d' article , ajoutons quelques attributs comme décrit ci-dessus.
< article itemscope itemtype = "http://schema.org/BlogPosting" > <!-- … --> </ article > L'ajout des itemscope et itemtype créera la structure de données initiale à utiliser par le navigateur. Définir son type sur " BlogPosting " permettra d'ajouter un ensemble spécifique de données sur les enfants.
2. En-tête et méta-contenu
Ensuite, nous ajouterons l'élément d'en- header avec les métadonnées de l'article de blog. Cela inclura des informations telles que le titre, la signature, la date de publication et l'auteur. Puisqu'il s'agit d'une page de destination complète pour un article de blog, nous utiliserons un h1 pour son texte de titre.
< article itemscope itemtype = "http://schema.org/BlogPosting" > < header > < h1 itemprop = "headline" > My Blog Post Title </ h1 > < p itemprop = "description" > A little extra on what this post is about </ p > < ul > < li > Written by < span itemprop = "author" itemscope itemtype = "http://schema.org/Person" > < span itemprop = "name" > Scott </ span > </ span > </ li > < li > < time datetime = "2020-01-09" itemprop = "dateCreated pubdate datePublished" > January 9th, 2020 </ time > </ li > </ ul > </ header > <!-- … --> </ article > Il y a beaucoup de contenu ici, alors décomposons-le.
- L'élément
h1a reçu l'itemprop="headline", le déclarant comme titre du message. - Le conteneur de contenu byline a l'
itemprop="description", qui déclare ce contenu comme description de l'article. -
Les données d'auteur nécessitent leur propre type de données "Personne". Comme nous devons déclarer un nouvel attribut
itemtype, nous incluons égalementitemscopepour commencer un nouveau nœud pour la structure de données. Ces données doivent être définies dans son propre élément HTML, enveloppant le contenu associé. Étant donné quespanest un élément en ligne et n'a aucune signification sémantique, il s'agit d'un élément sûr à utiliser.Le nom de l'auteur est ensuite entouré d'un autre
spanavec son attributitempropdéfini surname. -
Enfin, la date de l'article de blog utilise l'élément de
datesémantique qui comporte l'itemprop="dateCreated pubdate datePublished"pour définir la date de l'article.
3. Corps du contenu
Les derniers éléments à ajouter sont l'image de publication (facultative) et le corps du contenu.
< article itemscope itemtype = "http://schema.org/BlogPosting" >
< header > <!-- … --> </ header > < img src = "article-image.jpg" alt = "" itemprop = "image" /> < div itemprop = "articleBody" > < p > Lorem ipsum dolor sit ame, consectetur adipiscing elit. Donec a quam rhoncus, tincidunt ipsum non, ultricies augue… </ p > <!-- … --> </ div >
</ article >
Avec l' itemprop="articleBody" appliqué à l'élément wrapper div , notre structure de données sait qu'il s'agit du contenu textuel principal de la publication.
L' itemprop="image" appliqué à l'élément img le définit comme l'image principale de la publication.
Tout à fait maintenant !
Voici l'extrait de code HTML final avec tous les attributs de microdonnées ajoutés :
< article itemscope itemtype = "http://schema.org/BlogPosting" > < header > < h1 itemprop = "headline" > My Blog Post Title </ h1 > < p itemprop = "description" > A little extra on what this post is about </ p > < ul > < li > Written by < span itemprop = "author" itemscope itemtype = "http://schema.org/Person" > < span itemprop = "name" > Scott </ span > </ span > </ li > < li > < time datetime = "2020-01-09" itemprop = "dateCreated pubdate datePublished" > January 9th, 2020 </ time > </ li > </ ul > </ header > < img src = "article-image.jpg" alt = "" itemprop = "image" /> < div itemprop = "articleBody" > < p > Lorem ipsum dolor sit ame, consectetur adipiscing elit. Donec a quam rhoncus, tincidunt ipsum non, ultricies augue… </ p > <!-- … --> </ div >
</ article >Essayez-le dans mon exemple de microdonnées CodePen .
Tester la mise en œuvre des microdonnées
Si vous ajoutez des attributs de microdonnées à vos modèles, consultez l' outil de test des données structurées de Google. Vous pouvez ajouter une URL ou un code source directement et l'outil signalera les erreurs et les avertissements à votre structure.
En testant l'extrait de code HTML ci-dessus, cet outil a signalé certaines données manquantes qui étaient requises pour le type BlogPosting. Voici ce que j'ai ajouté pour satisfaire ces erreurs :
< div itemscope itemprop = "publisher" itemtype = "http://schema.org/Organization" > < meta itemprop = "name" content = "Company Name" > < span itemprop = "logo" itemscope itemtype = "http://schema.org/ImageObject" > < meta itemprop = "url" content = "logo.jpg" > </ span > </ div > Étant donné que ce contenu est uniquement destiné à la structure des données, nous pouvons utiliser l'élément meta HTML. Cela reste du HTML valide tant que seuls les itemprop et content sont inclus.
Vous pouvez accomplir la même chose en définissant CSS display: none sur un élément wrapper span , mais cela a des effets secondaires négatifs en ce qui concerne le référencement et d'autres problèmes liés à la structure des données.
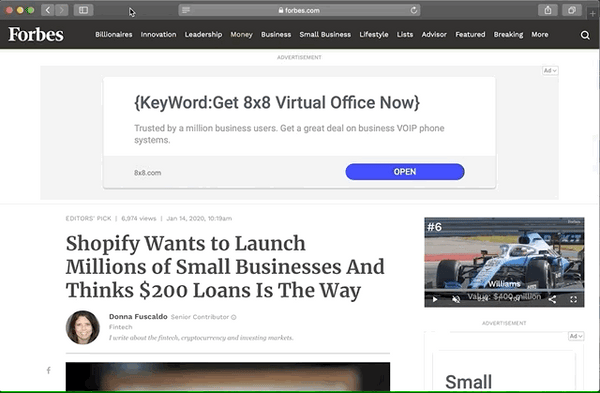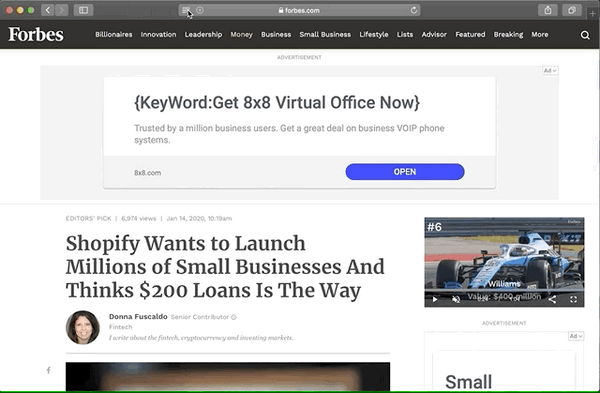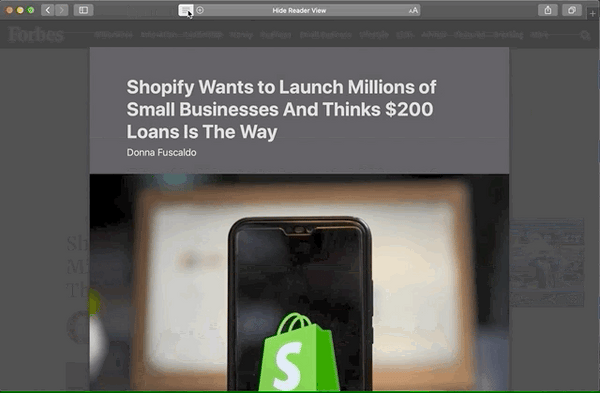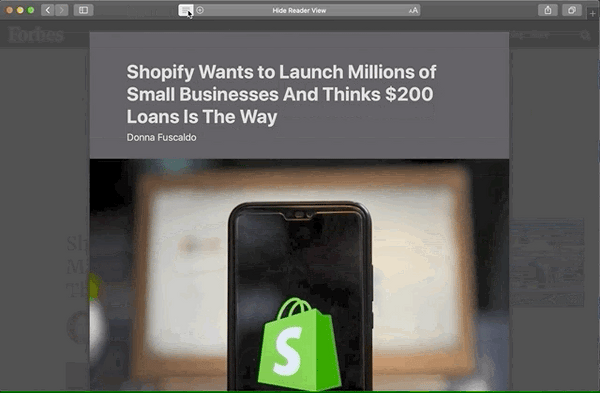
Comparaison du mode lecteur
Voici pourquoi je pense que ces attributs supplémentaires valent la peine d'être ajoutés. Passez en revue ces images avant et après du mode Safari Reader :
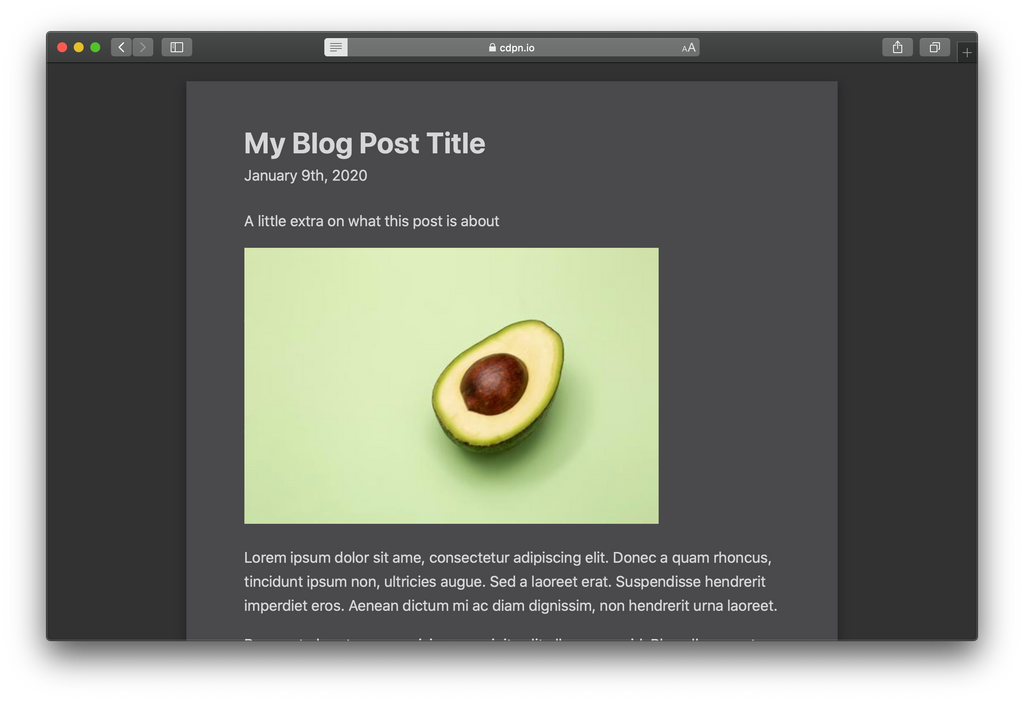
Avant de
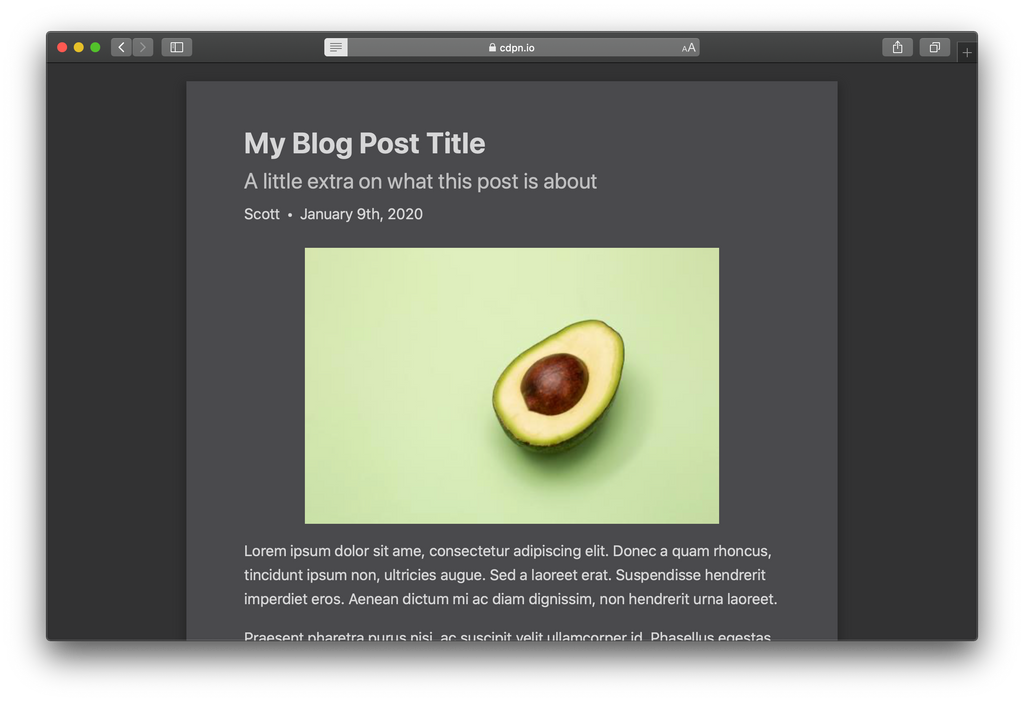
Après
Voici les principales différences avec les microdonnées appliquées :
- Byline est déplacé directement sous le titre avec un texte légèrement plus grand.
- L'auteur et la date sont formatés sur la même ligne, séparés par une puce.
- L'auteur s'affiche ! (Je ne sais pas pourquoi il serait caché avant. 🤔)
- L'image est centrée.
Conclusion
En incluant des attributs de microdonnées, la mise en page du mode lecteur offre désormais une capacité visuelle supplémentaire. Ces visuels aident à communiquer la structure et le but du contenu.
Lorsqu'il est appliqué au modèle, le mode lecteur fournira un style visuel cohérent, aidant les gens à consommer le contenu avec précision et facilité.
Et vraiment, c'est ce à quoi nous, en tant que concepteurs et développeurs du Web, devrions nous efforcer; en mettant l'accent sur la facilité d'utilisation et en créant une expérience confortable pour tous les lecteurs de notre contenu.
Ressources
- Spécification des microdonnées HTML du W3C
- Comprendre le fonctionnement des données structurées
- Mode lecteur : le bouton à battre
- Création de sites Web pour Safari Reader Mode et d'autres applications de lecture
- Outil de test de données structurées Google
- La valeur pratique du HTML sémantique
- Le contenu a besoin d'une date de publication !


