Wie helfen HTML-Mikrodaten bei der Barrierefreiheit?

Ich habe HTML aus einem Blog zur Barrierefreiheit studiert, das von einem blinden Entwickler geschrieben wurde. Ich war neugierig, wie sie ihr Markup strukturiert haben, und wollte sehen, ob es zusätzliche Bits gibt, die es noch zugänglicher machen.
Das Markup aus diesem speziellen Blog schien über das hinauszugehen, was ich als grundlegende semantische Struktur bezeichnen würde; article , header , logisch geordnete Überschriften usw. Es enthielt auch einige Attribute, die ich von früher kannte ( item-something ?), aber ich habe mir nie die Zeit genommen, etwas darüber zu lernen: Microdata .
Was sind Mikrodaten?
Mikrodaten, wie von schema.org und/oder der Microdata-Spezifikation beschrieben, sind Attribute, die Browsern dabei helfen, eine maschinenlesbare Datenstruktur aufzubauen, die von Browsern verwendet werden kann. Man kann es sich ähnlich wie ein JSON-Objekt als key:value -Paare vorstellen.
Nachdem Sie die Spezifikation gelesen und einige Beispiele überprüft haben, scheint es drei Hauptattribute zu geben, die Sie beachten sollten:
- Alles mit dem booleschen Attribut
itemscopeist das Element oder "Ding" der Daten, die Sie definieren. Es ist mehr oder weniger ein Container oder „Ausgangspunkt“ für Daten. - Ein Artikel benötigt das
itemtypeAttribut mit einem bestimmten URL-Wert, um das Vokabular oder die "Kategorie" des Artikels weiter zu beschreiben. Mit anderen Worten, was als untergeordnete Datenelemente akzeptabel ist. - Ein letztes Attribut, das in die Definition eines Elements aufgenommen werden muss, ist
itemprop. Dies ist der Eigenschaftsname des Datenknotens, den wir gerade definieren.
Hier der Kicker:
Mikrodaten helfen beim Auffinden und Anordnen von Inhalten für den Lesemodus des Browsers .
Was ist der Lesemodus?
Der Lesemodus ist eine Browserfunktion, die es jemandem erleichtert, sich auf Inhalte zu konzentrieren, indem er:
- Ausblenden von nicht wesentlichen Seitenelementen wie Navigation, Seitenleisten, Fußzeilen und Anzeigen
- Ändern der Textgröße, des Kontrasts und des Layouts der Seite für eine bessere Lesbarkeit
- Ablenkende Animationen entfernen
Dies hilft bei der Schaffung einer zugänglicheren Erfahrung für Menschen mit kognitiven Beeinträchtigungen oder Lernschwierigkeiten, wie z. B. Legasthenie, da alles Unnötige auf der Seite entfernt wird.
Hinzufügen von Mikrodaten zu einer Blogbeitragsvorlage
Lassen Sie uns etwas HTML für eine Blog-Post-Vorlage schreiben und die Mikrodaten-Attribute hinzufügen, die dabei helfen, ein besseres Lesemodus-Erlebnis zu schaffen.
1. Artikelbehälter
Fügen wir für das Containerelement article einige Attribute hinzu, wie oben beschrieben.
< article itemscope itemtype = "http://schema.org/BlogPosting" > <!-- … --> </ article > Durch das Hinzufügen der Attribute itemscope und itemtype wird die anfängliche Datenstruktur erstellt, die der Browser verwenden kann. Die Einstellung des Typs als " BlogPosting " ermöglicht das Hinzufügen eines bestimmten Satzes von Kinderdaten.
2. Header und Meta-Content
Als Nächstes fügen wir das header -Element zusammen mit den Metadaten des Blogposts hinzu. Dazu gehören Informationen wie Titel, Verfasser, Veröffentlichungsdatum und Autor. Da dies eine vollständige Zielseite für einen Blogpost ist, verwenden wir h1 für den Titeltext.
< article itemscope itemtype = "http://schema.org/BlogPosting" > < header > < h1 itemprop = "headline" > My Blog Post Title </ h1 > < p itemprop = "description" > A little extra on what this post is about </ p > < ul > < li > Written by < span itemprop = "author" itemscope itemtype = "http://schema.org/Person" > < span itemprop = "name" > Scott </ span > </ span > </ li > < li > < time datetime = "2020-01-09" itemprop = "dateCreated pubdate datePublished" > January 9th, 2020 </ time > </ li > </ ul > </ header > <!-- … --> </ article > Es gibt hier eine Menge Inhalt, also lasst es uns aufschlüsseln.
- Das Element
h1erhielt dasitemprop="headline"und deklarierte dies als Titel des Beitrags. - Der Byline-Inhaltscontainer hat das
itemprop="description", das diesen Inhalt als Beitragsbeschreibung deklariert. -
Autorendaten benötigen einen eigenen Datentyp "Person". Da wir ein neues
itemtypeAttribut deklarieren müssen, schließen wir auchitemscopeein, um einen neuen Knoten für die Datenstruktur zu beginnen. Diese Daten müssen in ein eigenes HTML-Element gesetzt werden, das den zugehörigen Inhalt umschließt. Daspanein Inline -Element ist und keine semantische Bedeutung hat, ist dies ein sicheres Element.Der Name des Autors wird dann mit einem weiteren
spanumschlossen, dessen Attributitempropaufnamegesetzt ist. -
Schließlich verwendet das Datum des Blogbeitrags das semantische
date, das das Attributitemprop="dateCreated pubdate datePublished", um das Datum des Beitrags festzulegen.
3. Inhaltskörper
Die letzten hinzuzufügenden Teile sind das (optionale) Beitragsbild und der Inhaltstext.
< article itemscope itemtype = "http://schema.org/BlogPosting" >
< header > <!-- … --> </ header > < img src = "article-image.jpg" alt = "" itemprop = "image" /> < div itemprop = "articleBody" > < p > Lorem ipsum dolor sit ame, consectetur adipiscing elit. Donec a quam rhoncus, tincidunt ipsum non, ultricies augue… </ p > <!-- … --> </ div >
</ Artikel >
Wenn das Attribut itemprop="articleBody" auf das Wrapper- div -Element angewendet wird, weiß unsere Datenstruktur, dass dies der primäre Textinhalt des Beitrags ist.
Das auf das img -Element angewendete itemprop="image" legt dieses als Hauptpostbild fest.
Jetzt alles zusammen!
Hier ist das endgültige HTML-Snippet mit allen hinzugefügten Mikrodatenattributen:
< article itemscope itemtype = "http://schema.org/BlogPosting" > < header > < h1 itemprop = "headline" > My Blog Post Title </ h1 > < p itemprop = "description" > A little extra on what this post is about </ p > < ul > < li > Written by < span itemprop = "author" itemscope itemtype = "http://schema.org/Person" > < span itemprop = "name" > Scott </ span > </ span > </ li > < li > < time datetime = "2020-01-09" itemprop = "dateCreated pubdate datePublished" > January 9th, 2020 </ time > </ li > </ ul > </ header > < img src = "article-image.jpg" alt = "" itemprop = "image" /> < div itemprop = "articleBody" > < p > Lorem ipsum dolor sit ame, consectetur adipiscing elit. Donec a quam rhoncus, tincidunt ipsum non, ultricies augue… </ p > <!-- … --> </ div >
</ Artikel >Probieren Sie es in meinem Mikrodatenbeispiel CodePen aus .
Testen Sie die Implementierung von Mikrodaten
Wenn Sie Ihren Vorlagen Mikrodatenattribute hinzufügen, sehen Sie sich das Testtool für strukturierte Daten von Google an. Sie können direkt eine URL oder einen Quellcode hinzufügen und das Tool meldet Fehler und Warnungen an Ihre Struktur.
Beim Testen des obigen HTML-Snippets hat dieses Tool einige fehlende Daten gemeldet, die für den BlogPosting-Typ erforderlich waren. Folgendes habe ich hinzugefügt, um diese Fehler zu beheben:
< div itemscope itemprop = "publisher" itemtype = "http://schema.org/Organization" > < meta itemprop = "name" content = "Company Name" > < span itemprop = "logo" itemscope itemtype = "http://schema.org/ImageObject" > < meta itemprop = "url" content = "logo.jpg" > </ span > </ div > Da dieser Inhalt nur der Datenstruktur dient, können wir das HTML- meta -Element verwenden. Dies bleibt gültiges HTML, solange nur die itemprop und content -Attribute enthalten sind.
Sie könnten dasselbe erreichen, indem Sie CSS display: none für ein Wrapper- span -Element festlegen, aber dies hat negative Nebenwirkungen, wenn es um SEO und andere Probleme im Zusammenhang mit der Datenstruktur geht.
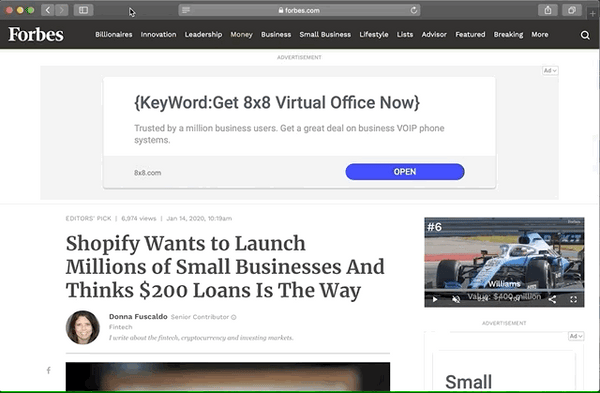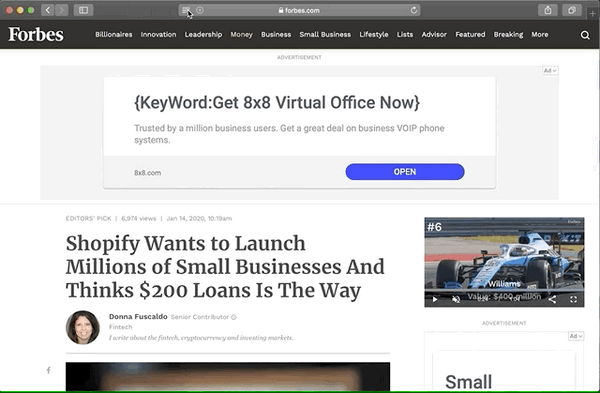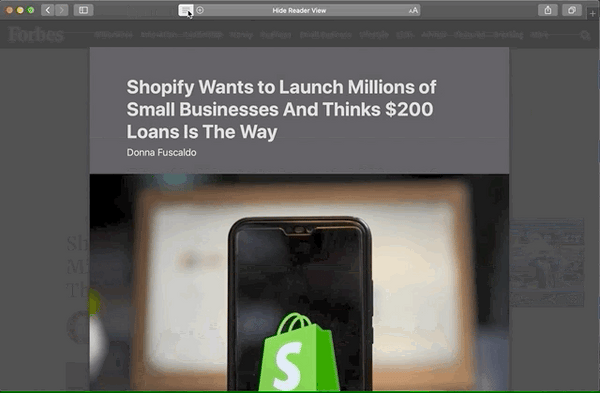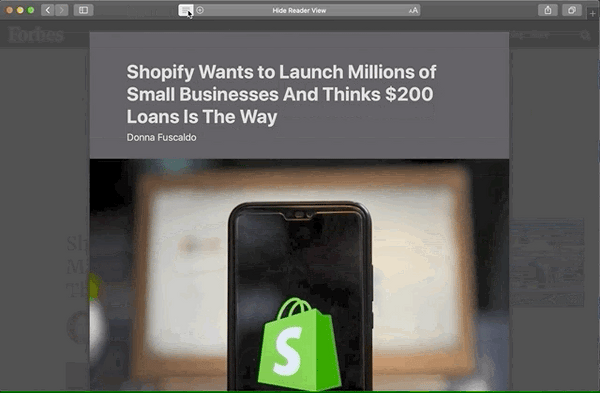
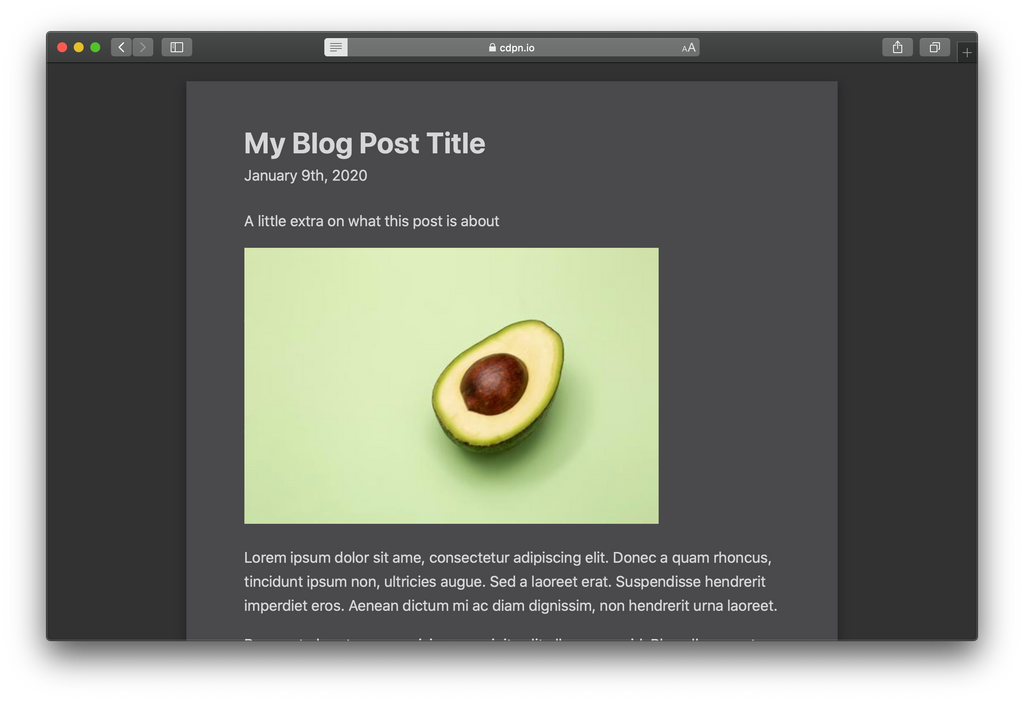
Lesemodus-Vergleich
Deshalb finde ich, dass diese zusätzlichen Attribute es wert sind, hinzugefügt zu werden. Sehen Sie sich diese Vorher-Nachher-Bilder aus dem Safari-Reader-Modus an:
Vor
Nach
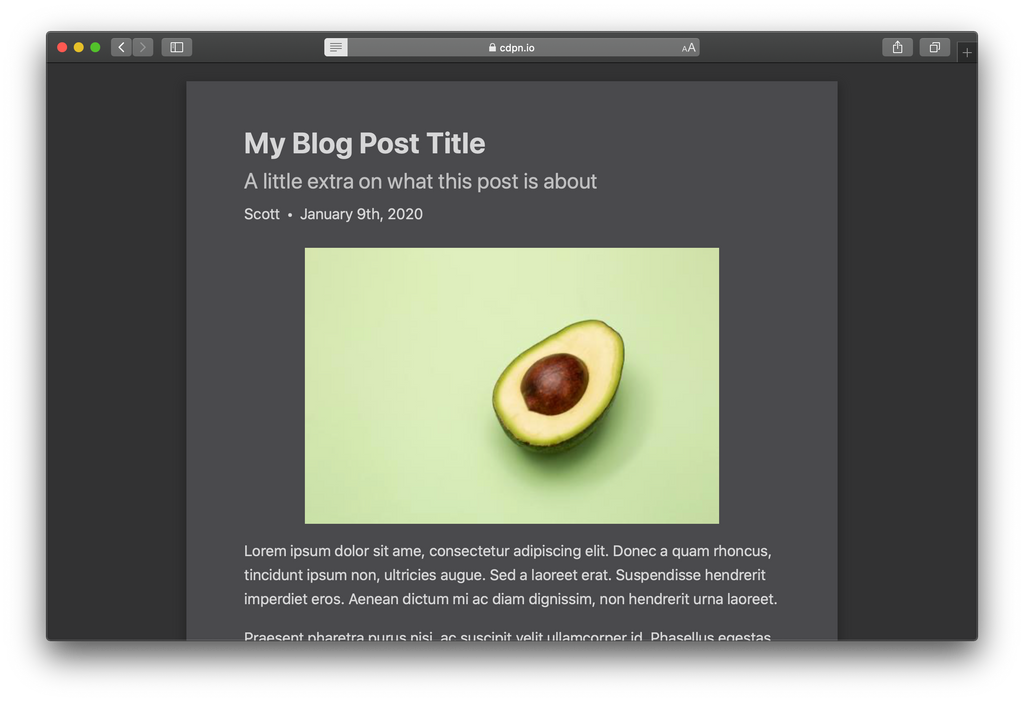
Hier sind die Hauptunterschiede bei angewendeten Mikrodaten:
- Byline wird mit etwas größerem Text direkt unter den Titel verschoben.
- Autor und Datum werden in derselben Zeile formatiert, getrennt durch ein Aufzählungszeichen.
- Der Autor wird angezeigt! (Ich bin mir nicht sicher, warum es vorher ausgeblendet wurde. 🤔)
- Das Bild ist zentriert ausgerichtet.
Fazit
Durch die Einbeziehung von Mikrodatenattributen bietet das Layout des Lesemodus jetzt zusätzliche visuelle Möglichkeiten. Diese visuellen Elemente helfen bei der Vermittlung von Struktur und Zweck des Inhalts.
Wenn der Lesemodus auf die Vorlage angewendet wird, bietet er einen konsistenten visuellen Stil, der den Benutzern hilft, Inhalte genau und einfach zu lesen.
Und genau danach sollten wir als Designer und Entwickler des Webs streben; Wir konzentrieren uns auf Benutzerfreundlichkeit und schaffen ein komfortables Erlebnis für alle Leser unserer Inhalte.
Ressourcen
- W3C-HTML-Mikrodatenspezifikation
- Verstehen Sie, wie strukturierte Daten funktionieren
- Lesemodus: Der Knopf zum Schlagen
- Erstellen von Websites für den Safari Reader Mode und andere Lese-Apps
- Testtool für strukturierte Daten von Google
- Der praktische Wert von semantischem HTML
- Inhalte benötigen ein Veröffentlichungsdatum!